
PostgreSQL - Räkna alla personer som är lika gamla och lista resultaten efter ålder
Uppgift:
For this challenge you need to create a simple GROUP BY statement, you want to group all the people by their age and count the people who have the same age.
people table schema
- id
- name
- age
select table schema
age [group by]
people_count (people count)
NOTE: Your solution should use pure SQL. Ruby is used within the test cases to do the actual testing.
Källa: https://www.codewars.com/kata/sql-basics-simple-group-by/train/sql
Mitt försök att lösa uppgiften (PostgreSQL 9.6):
select age, count(age) as people_count from people
group by age
having age = people.age
Output: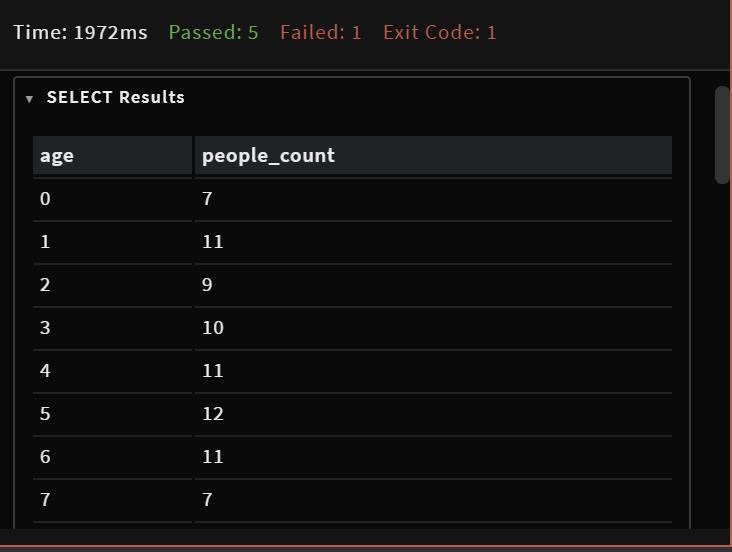 Fråga:
Fråga:
Enligt felmeddelandet så skiljer sig mina utvärden med förväntade utvärden. Jag har kikat på förväntade utvärden, och jag kan inte se att några av mina utvärden skiljer sig åt. Någon som vet vad jag gjort för fel?

Hur ser de förväntade utvärdena ut?
Behövs förresten "having age = people.age"?
Laguna skrev:Hur ser de förväntade utvärdena ut?
Behövs förresten "having age = people.age"?
Behöver jag inte använda having för att jämföra de personer som är lika gamla?
Här följer de förväntade resultaten tillsammans med mina resultat:
Test Failed expected: [{:age=>8, :people_count=>12}, {:age=>4, :people_count=>15}, {:age=>1, :people_count=>9}, {:age=>5, :..._count=>9}, {:age=>6, :people_count=>8}, {:age=>2, :people_count=>12}, {:age=>7, :people_count=>10}] got: [{:age=>0, :people_count=>4}, {:age=>1, :people_count=>9}, {:age=>2, :people_count=>12}, {:age=>3, :p..._count=>8}, {:age=>7, :people_count=>10}, {:age=>8, :people_count=>12}, {:age=>9, :people_count=>9}] (compared using ==) Diff: @@ -1,11 +1,11 @@ -[{:age=>8, :people_count=>12}, - {:age=>4, :people_count=>15}, +[{:age=>0, :people_count=>4}, {:age=>1, :people_count=>9}, - {:age=>5, :people_count=>12}, + {:age=>2, :people_count=>12}, {:age=>3, :people_count=>9}, - {:age=>0, :people_count=>4}, - {:age=>9, :people_count=>9}, + {:age=>4, :people_count=>15}, + {:age=>5, :people_count=>12}, {:age=>6, :people_count=>8}, - {:age=>2, :people_count=>12}, - {:age=>7, :people_count=>10}] + {:age=>7, :people_count=>10}, + {:age=>8, :people_count=>12}, + {:age=>9, :people_count=>9}]
Jag tycker GROUP borde räcka. Men behövs det så behövs det.
Det du får och det som förväntas är inte alls lika. Det är lika många rader, men vissa finns bara i den ena listan.
Laguna skrev:Jag tycker GROUP borde räcka. Men behövs det så behövs det.
Det du får och det som förväntas är inte alls lika. Det är lika många rader, men vissa finns bara i den ena listan.
Koden klarade alla test när jag tog bort "having age = people.age" :)
Är det så att GROUP BY körs före själva uträkningen i SELECT?
TB16 skrev:Laguna skrev:Jag tycker GROUP borde räcka. Men behövs det så behövs det.
Det du får och det som förväntas är inte alls lika. Det är lika många rader, men vissa finns bara i den ena listan.
Koden klarade alla test när jag tog bort "having age = people.age" :)
Är det så att GROUP BY körs före själva uträkningen i SELECT?
Det här HAVING känner jag inte igen. Antingen är det nåt man använder relativt sällan, eller så är det specifikt för PostgreSQL (som jag inte har använt).
Om man alltid kan se GROUP BY som något som görs efter SELECT vågar jag inte svara på. Varför frågar du det?
Laguna skrev:TB16 skrev:Laguna skrev:Jag tycker GROUP borde räcka. Men behövs det så behövs det.
Det du får och det som förväntas är inte alls lika. Det är lika många rader, men vissa finns bara i den ena listan.
Koden klarade alla test när jag tog bort "having age = people.age" :)
Är det så att GROUP BY körs före själva uträkningen i SELECT?
Det här HAVING känner jag inte igen. Antingen är det nåt man använder relativt sällan, eller så är det specifikt för PostgreSQL (som jag inte har använt).
Om man alltid kan se GROUP BY som något som görs efter SELECT vågar jag inte svara på. Varför frågar du det?
Okej, anledningen till att jag frågade var för att jag inte riktigt förstod hur man kunde lösa uppgiften utan ett villkor som jämför om person x har samma ålder som person y.

Man kan i princip säga att först körs WHERE, sedan GROUP BY och sist HAVING.
Nu har du ingen WHERE, så alla rader kommer med till grupperingen, men säg att du bara ville räkna ut tabellen på personer som hette något på A så kunde du haft WHERE name LIKE 'A%'. Här väljer man alltså vilka poster i tabellen som ska vara med till sammanslagningen/grupperingen.
GROUP BY slår ihop alla rader (som matchade where) som har samma värde i de angivna fälten, i ditt fall age. Då den slår ihop exempelvis raden "1,Nisse,7" med "2,Anna,7" så kan man inte längre använda fälten id och name, för det fanns (kanske) olika värden där, och en strikt SQL-motor ger ett fel ifall man gör t.ex "SELECT name,age FROM pople GROUP BY age" av den anledningen. Man kan således normalt bara selecta de fält som finns med i group-by, samt så kallade aggregerings-funktioner, som COUNT, MAX och liknande, som gör en funktion på alla raderna som ingår i den gruppen, vilket i ditt fall blir alla rader som har samma age. Du kan alltså lika gärna skriva COUNT(*) AS people_count.
HAVING används sedan om man vill göra ytterligare urval på det sammaslagna resultatet, för saker som man inte kan kolla redan i WHERE. Exempelvis kanske du bara vill se antalet i åldrarna som har minst tio personer, då kan man lägga på HAVING people_count>=10. (I HAVING kan man alltså använda alias-namnet efter AS, vilket man inte kan i WHERE.)
Vad som händer när man tar med en tabell-kolumn i having som du först gjorde med pople.age vet jag inte riktigt, jag tror inte det är normalt att göra så, men jag kan tycka att det antingen borde varit en no-op, eller att den skulle spottat ut sig ett error. Men om jag tolkar fel-diffen rätt så var enda skillnaden att din och facits lista var sorterade olika (och då det inte angavs i frågan hur man skulle sortera borde den ju gett rätt). Ofta sorteras det på de fält man anger i GROUP BY, men jag tror inte det är något man kan förutsätta, det beror väl bl.a på vilken SQL-motor man har, så man kanske kan läsa sig till det.
Nja, som jag skrev så är resultatlistorna lika långa, men innehåller delvis olika saker.
jek7 skrev:Man kan i princip säga att först körs WHERE, sedan GROUP BY och sist HAVING.
Nu har du ingen WHERE, så alla rader kommer med till grupperingen, men säg att du bara ville räkna ut tabellen på personer som hette något på A så kunde du haft WHERE name LIKE 'A%'. Här väljer man alltså vilka poster i tabellen som ska vara med till sammanslagningen/grupperingen.
GROUP BY slår ihop alla rader (som matchade where) som har samma värde i de angivna fälten, i ditt fall age. Då den slår ihop exempelvis raden "1,Nisse,7" med "2,Anna,7" så kan man inte längre använda fälten id och name, för det fanns (kanske) olika värden där, och en strikt SQL-motor ger ett fel ifall man gör t.ex "SELECT name,age FROM pople GROUP BY age" av den anledningen. Man kan således normalt bara selecta de fält som finns med i group-by, samt så kallade aggregerings-funktioner, som COUNT, MAX och liknande, som gör en funktion på alla raderna som ingår i den gruppen, vilket i ditt fall blir alla rader som har samma age. Du kan alltså lika gärna skriva COUNT(*) AS people_count.
HAVING används sedan om man vill göra ytterligare urval på det sammaslagna resultatet, för saker som man inte kan kolla redan i WHERE. Exempelvis kanske du bara vill se antalet i åldrarna som har minst tio personer, då kan man lägga på HAVING people_count>=10. (I HAVING kan man alltså använda alias-namnet efter AS, vilket man inte kan i WHERE.)
Vad som händer när man tar med en tabell-kolumn i having som du först gjorde med pople.age vet jag inte riktigt, jag tror inte det är normalt att göra så, men jag kan tycka att det antingen borde varit en no-op, eller att den skulle spottat ut sig ett error. Men om jag tolkar fel-diffen rätt så var enda skillnaden att din och facits lista var sorterade olika (och då det inte angavs i frågan hur man skulle sortera borde den ju gett rätt). Ofta sorteras det på de fält man anger i GROUP BY, men jag tror inte det är något man kan förutsätta, det beror väl bl.a på vilken SQL-motor man har, så man kanske kan läsa sig till det.
Väldigt ingående och informativt svar :) Stort tack! Det stärkte min förståelse
