
Går det att avgöra vid vilket n som man kan applicera centrala gränsvärdessatsen?
Hej!
Jag satt med följande uppgift (6.24 i Sannolikhetsteori och statistiktteori med tillämpningar av Gunnar Blom m.fl.)
Vi har att är oberoende mätfel med (alla mätfel är likafördelade). Låt och beräkna approximativt då
Som jag har förstått det så är det så här Centrala Gränsvärdessatsen / C.G.S. fungerar:
Givet att är stokastiska variabler som är oberoende och likafördelade med väntevärdet och med standardavvikelsen där så gäller att summan av de, dvs. är approxmativt normalfördelad med om (antalet stokastiska variabler) är många.
Nu i efterhand när jag läser uppgiften igen inser jag att det finns en nyckelfras i frågan som hintar om att jag kan använda C.G.S, beräkna approximativt. Fortfarande undrar jag om det finns något sätt att avgöra om (antalet stokastiska variabler som summeras) är tillräckligt stort för att C.G.S. ska appliceras?
Jag hoppas att ni förstår min fråga.

Jag är rostig här men gör ett försök.
Om sigma för en mätning är 8 så är
standardavv för medelvärdet av n mätningar = 8/(roten ur n)
Så vi har s för 16 mätn = 2 (a)
s för 1600 mätn = 0,2 (b)
s för 16 00 00 mätn = 0,02 (c)
Vi har en gräns 0,08
I (a) motsvarar gränsen 0,04 s
I (b) motsv gränsen 0,4 s
I (c) motsv gränsen 4 s
Sedan bör man med en tabell kunna hitta de sökta sannolikheterna.
Jag har ingen tillgänglig tabell över normalförd, men det tycks som att sh är nära 1 i (a) och mycket nära 0 i (c). (Sannolikheten att en stok variabel som är N(0 , 1) ska hamna mer än fyra enheter från 0 är Jätteliten.)
Tillägg: 12 apr 2025 19:49
EDIT
Samtliga mina inlägg här kan kasseras, de bygger på en felläsning av uppgiften.

Jag har inte boken framför mig men det verkar som att uppgiften försöker visa att slh-värdena via approximationen för låga n är tvivelaktiga då värdet för n=16 är 0.96814, n=1600 0.72389 och n=160 000 0.84134.
Jag har en gång läst denna bok och kommer ihåg appendix med ändlösa fördelnings/slh-tabeller. Använder man dessa än idag, då dagens räknare kan ge dessa värden på ett enklare sätt. Samma sak gäller omskrivningen av s.v. till N(0,1) som, med räknare, är helt meningslös och endast av betydelser vid tabeller (som känns som 1940-tal idag).
Trinity2 skrev:Jag har inte boken framför mig men det verkar som att uppgiften försöker visa att slh-värdena via approximationen för låga n är tvivelaktiga då värdet för n=16 är 0.96814, n=1600 0.72389 och n=160 000 0.84134.
Jag har en gång läst denna bok och kommer ihåg appendix med ändlösa fördelnings/slh-tabeller. Använder man dessa än idag, då dagens räknare kan ge dessa värden på ett enklare sätt. Samma sak gäller omskrivningen av s.v. till N(0,1) som, med räknare, är helt meningslös och endast av betydelser vid tabeller (som känns som 1940-tal idag).
Tack för synpunkt. Jo, tabeller är nog obsoleta. De doftar 40-tal, liksom jag.
Det intressanta tycker jag är att om n ändras med faktor c2 så ändras stickprovsstandardavvikelsen med faktor 1/c. Statistikformler är en skog som är svår att överblicka för alla träd.
Du skriver:
”…värdet för n=16 är 0.96814, n=1600 0.72389 och n=160 000 0.84134.”
Ser konstigt ut. Har du skrivit rätt här?
Jag tar på mig ärmskydden och går bort till min tavla med kritan i högsta hugg!!! Viva 1940!
Jag får:
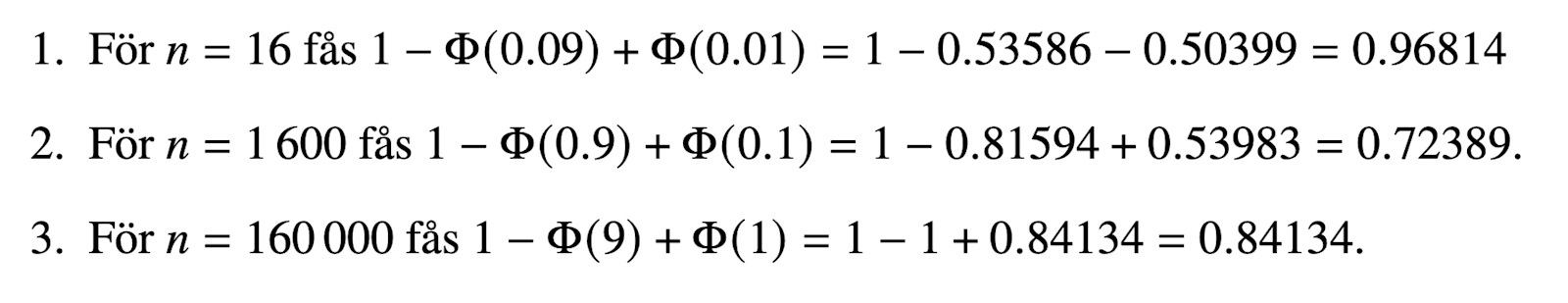
Så du menar att sannoloikheten är högst vid n = 16, minst vid n = 1600, och mittemellan vid n = 160000?
Jag får med en tabell från nätet (låt X vara stickprovsmedelvärde)
P[|X| > 0,08] = 0,48405+0,48405 = 0,9681 för n = 16
= 0,3446 + 0,3446 = 0,6892 för n = 1600
= 0,00003 + 0,00003 < 7*10–5 för n = 160 000.
Jag kan ha fel (sådant har hänt), men om dina värden är riktiga så har jag inte förstått något alls. Det märkliga är att vi får samma svar för n = 16.
Marilyn skrev:Jag får med en tabell från nätet (låt X vara stickprovsmedelvärde)
P[|X| > 0,08] = 0,48405+0,48405 = 0,9681 för n = 16
= 0,3446 + 0,3446 = 0,6892 för n = 1600
= 0,00003 + 0,00003 < 7*10–5 för n = 160 000.
Jag kan ha fel (sådant har hänt), men om dina värden är riktiga så har jag inte förstått något alls. Det märkliga är att vi får samma svar för n = 16.
Vilka phi-argument har du?
Sorry, jag vet inte vad phi-argument är.
Men jag frågade först – anser du att sannolikheten för att [stickprovsmedelvärdet avviker mer än 0,08 från 0] blir större om n ökas från sextonhundra till etthundrasextiotusen?
Det låter som ett argument mot dyra undersökningar med många observationer.
phi-arg är indata till N(0,1) eller kanske den heter z-tabellen i Bloms bok.
Nej, n=16 är ett medelvärde på 16 observationer vilket ger 16-dim normalfördelning som man inte vill beräkna exakt. Troligen speglar värdet 0.97 en grov felapproximation, p.g.a. av det låga antalet. När n ökar blir approximationen bättre via
https://sv.wikipedia.org/wiki/Centrala_gr%C3%A4nsv%C3%A4rdessatsen
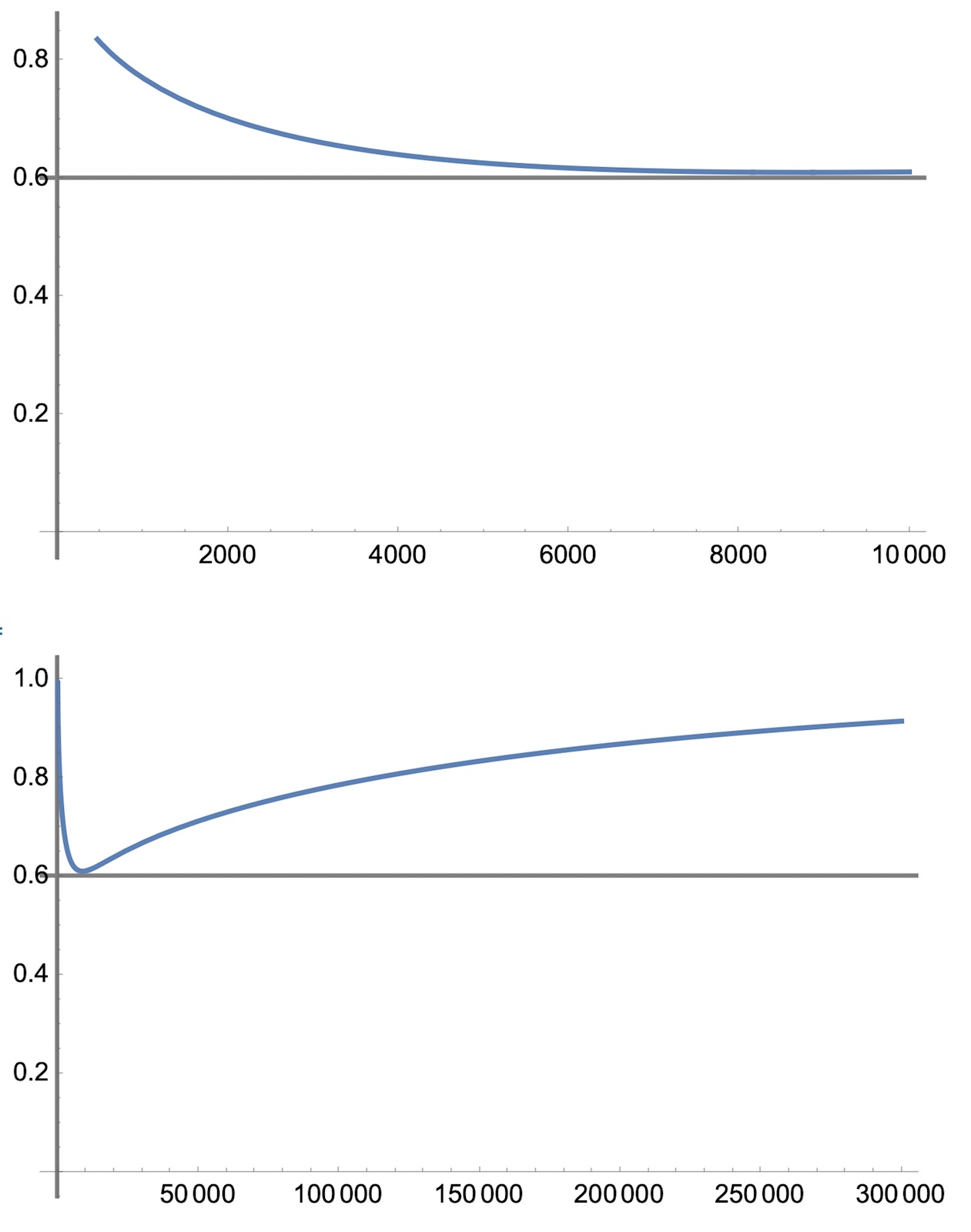
och vi ser att den planar ut mot 1 gå n->oo då de två sista termerna ->1
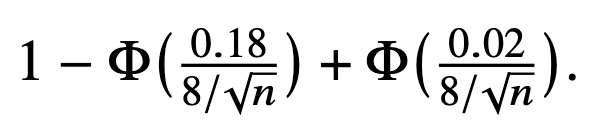
Första bilden visar grafen för låga n och den vänder runt c. 0.6 med ökande n.
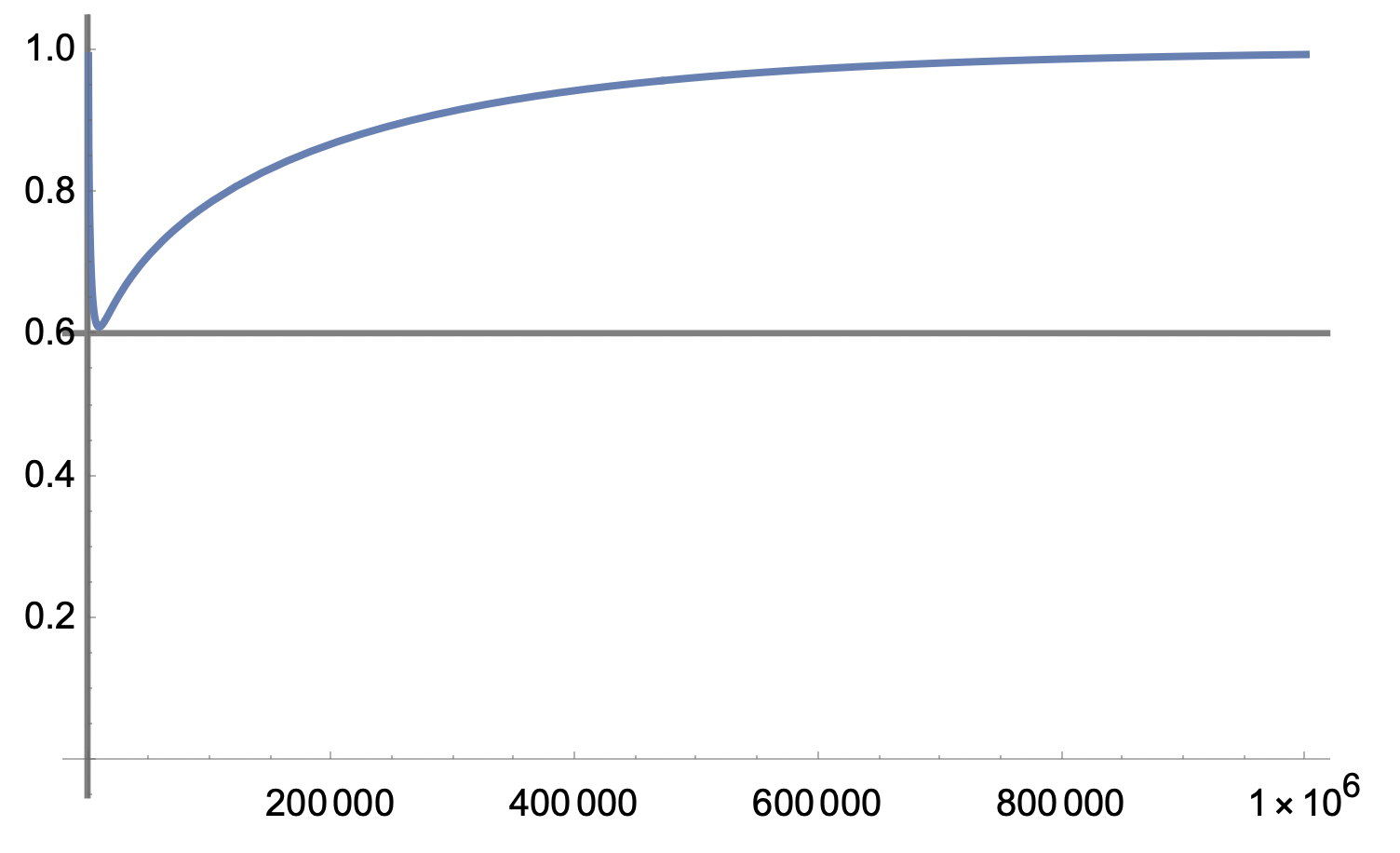
det verkar som att uppgiften försöker visa att slh-värdena via approximationen för låga n är tvivelaktiga
Det finns ingen notering om detta i facit, så det var väl lite min fråga.
Jag får rätt (enligt facit) för om jag kör att
(facit säger )
Använder man dessa än idag, då dagens räknare kan ge dessa värden på ett enklare sätt
Jajemän, de används än idag. Iallafall av min kurs :)
coffeeshot, har du facit för 1600 och 160000 också?
Marilyn skrev:coffeeshot, har du facit för 1600 och 160000 också?

Tack Trinity2, då är det något i uppgiften som jag inte alls har förstått. Jag tycker den är glasklar, jag kan ha räknat fel, eller läst fel i tabellen, men svaret i facit ter sig helt orimligt.
Marilyn skrev:Tack Trinity2, då är det något i uppgiften som jag inte alls har förstått. Jag tycker den är glasklar, jag kan ha räknat fel, eller läst fel i tabellen, men svaret i facit ter sig helt orimligt.
Jag fann detta i mina gömmor...

(något jag laddat ner för många år sedan... verkar OK)
Jej sir fejlet!
Väntevärdet är 0.1
Med mina svaga ögon läste jag
Väntevärdet är 0
punkt
Ny mening som börjar med en etta.
Detta innebär förstås att mina uträkningar, som bygger på att väntevärdet var noll komma nollnollnoll…, är helt värdelösa.
Tack för tålamodet.
Marilyn skrev:Jej sir fejlet!
Väntevärdet är 0.1
Med mina svaga ögon läste jag
Väntevärdet är 0
punkt
Ny mening som börjar med en etta.
Detta innebär förstås att mina uträkningar, som bygger på att väntevärdet var noll komma nollnollnoll…, är helt värdelösa.
Tack för tålamodet.
Det förklarar felet. Uppgiften förenklas dock ej med mu=0 (kanske något aritmetiskt, men inte statistiskt) varför vi nöjer oss med -1p i avdrag :). Och ja, textrendering är långt ifrån optimal på PA, 0.1 eller 0. 1 ...
Uppgiften saknar någon högre dimension utöver det mekaniska räknandet. Blom borde följt upp med en d-fråga om varför värdena blir som de blir. Hela uppgiften är enbart mekanik som man inte lär sig mycket av avs. antalet termer i medelvärdet vilket egentligen är uppgiftens kärna.
Det var mycket irriterande. Jag är ingen statistiktarzan, och vet inte om jag var fel ute i min lösning, men era lösningar var sånt komplett nonsens (med min felläsning), att jag undrade om jag var utsatt för mobbing.
–1 poäng avdrag, det är +1 p det. Tackar och bugar.
PS Frågan hur stort n ska vara för att approximationen ska bli godtagbar är väl oklar ifall man inte vet vilken fördelning X har. Jag misstänker att det kan slå rätt olika.
Marilyn skrev:Det var mycket irriterande. Jag är ingen statistiktarzan, och vet inte om jag var fel ute i min lösning, men era lösningar var sånt komplett nonsens (med min felläsning), att jag undrade om jag var utsatt för mobbing.
–1 poäng avdrag, det är +1 p det. Tackar och bugar.
PS Frågan hur stort n ska vara för att approximationen ska bli godtagbar är väl oklar ifall man inte vet vilken fördelning X har. Jag misstänker att det kan slå rätt olika.
Ja, fördelningen spelar in och konfidensgraden, men man brukar lägga sig på 1000 personer vid undersökningar där normalfördelning ligger och lurar i bakgrunden, direkt eller indirekt via approximation, om jag minns rätt. Jag får läsa lite i Blom, om det står där. Tidigare fanns bok A och B (A=slh-teori, B=statistik-teori), två rejäla böcker, men idag är det nog bok C (*lite* av varje, "best of") som finns kvar och används. Men det borde ingå ändå.

Frågan "för vilket n" är ju egentligen en praktisk fråga, alltså en fråga om vilken grad av precision som behövs och beror som konstaterats ovan på fördelningen. Vissa fördelningar konvergerar snabbt mot normalfördelning, andra långsamt.
Teorin om detta är faktiskt ganska djup men som tumregel; hur snabb konvergensen är beror på hur stor kvoten E[|X|^3]/Var(X) är. Så konvergensen går snabbt för symmetriskt fördelade variabler och långsamt för skevt fördelade variabler.
De riktigt krångliga fördelningar är de där E[|X|^3] är oändligt, i sådana fall kan man säga att centrala gränsvärdessatsen bara är av teoretiskt intresse, någon verklig konvergens kommer du aldrig observera i en tillämpning.
Förlåt för sent svar hörni men tack för er input. "Det beror på" är min takeaway. Tack!
