
Matte för kvantitativa forskningsmetoder
jag behöver hjälp! Jag pluggar andra året på en samhällsinriktad linje på universitet och läser just nu kursen ”kvantitativa metoder”. Det är en hel del siffror och matte i detta och jag fattar ingenting. Det finns massor av begrepp och formler jag behöver lära mig att förstå,
exempelvis;
Standardavvikelse
normalfördelning
konfidensintervall
kan nån hjälpa mig?

Den här bilden som jag tog på mitt gym är ett ganska kul exempel på en normalfördelning. Man kan se hur pinnen som håller fast vikterna har skavt olika mycket på vikterna eftersom de har blivit valda olika antal gånger. Väntevärdet ser ut att ligga någonstans runt 55 kg, dvs den vikt man förväntar sig att en person skulle välja. Sen finns det en del, fast färre, personer som har valt lättare och tyngre vikter där det har skavt mindre.

Standardavvikelsen säger hur mycket observationerna sprider från väntevärdet. Om standardavvikelsen är liten så skulle nötningen vara stor runt hålen nära 55 kg med liten/ingen nötning på lättare och tyngre vikter. Om standardavvikelsen är hög skulle det vara mer jämnt nött över alla vikter. Rent matematiskt ligger ca 2/3 (68%) av alla observationer inom +/- en standardavvikelse från väntevärdet i en normalfördelning. Om standardavvikelsen i det här fallet är 5 kg så betyder det att 2/3 av alla personer som använder maskinen skulle välja vikter inom intervallet 55 +/- 5 kg.
Konfidensintervall är ett sätt att skatta osäkerheten i en mätning. Säg att vi misstänker att de som går till mitt gym och använder maskinen har blivit starkare, hur skulle vi då kunna mäta det? Jo man skulle kunna notera vad t.ex. 10 personer väljer för vikt och beräkna ett medelvärde. Säg att det blir 65 kg. Betyder det att besökarna har blivit starkare eftersom vi förväntade oss värdet 55 kg i snitt? Nej, för vi har bara tagit ett stickprov och kontrollerat ett fåtal besökare. Vi har inte kontrollerat alla besökare som någonsin har gått till gymmet, vilket man matematiskt kallar för "populationen". Då beräknar man ett konfidensintervall, vilket för vår observation kanske skulle bli 45-65 kg med en konfidensgrad på 95%. Vad det innebär är att om vi fortsatte att mäta och beräkna konfidensintervall så skulle vi fånga det "sanna" värdet inom intervallet i 95% av gångerna. Ju snävare konfidensintervallet är, desto säkrare är skattningen. Man kan t.ex. få ett snävare konfidensintervall genom att öka antalet mätningar, t.ex. mäta på 100 istället för 10 personer.
Tack! Jag tror jag förstår lite bättre nu vad konfidensintervall och standardavvikelse innebär men siffror och jag är inte bästa vänner.
Det jag fortfarande inte fattar är vad en normalfördelning är? Jag får inget grepp om det. Som det står i min kurslitteratur så är det variationen mellan stickprovets medelvärde och populationens medelvärde som uppstår när man gör ett oändligt antal stickprov. Men det gör det oklart för mig, varför skulle man ens dra ett oändligt antal stickprov?
Boken tar också upp medelvärdets standardfel. Är det samma som standardavvikelse? Som jag fattat det så handlar medelvärdets standardfel om att man gör en skattning av hur mycket stickprovets genomsnitt sannolikt kommer skilja sig från populationens genomsnitt och att om 95 % hamnar inom spannet -1.96 till +1.96 standardfel så betraktar man resultaten som tillförlitliga. Är detta korrekt, stämmer det att det är samma som standardavvikelse då?
Stort och hjärtligt tack för att du tog dig tid att svara =)
Normalfördelning är helt enkelt en fördelning man uppmärksammar lite här och var i naturen och på andra platser, som i mitt exempel. Det som är lite speciellt med normalfördelningen är att alla andra fördelningar kan göras om till en normalfördelning via något som kallas centrala gränsvärdessatsen, vilket är det som din kurslitteratur använder till definitionen.
Exempel: Om man kastar en tärning så är utfallet rektangulärt fördelat, dvs det är 1/6 sannolikhet att få t.ex. en 3:a eller en 6:a. I snitt förväntar vi oss att utfallet blir (1+2+3+4+5+6)/6=3,5. Alla utfall är lika sannolika, med sannolikheten 1/6=16,67% att få ett visst utfall (1-6).
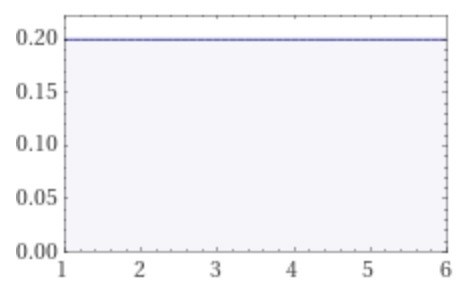
Detta är alltså inte en normalfördelning. Men vi skulle kunna göra om det till en sådan genom att kasta tärning ett antal gånger, beräkna medelvärdet av kasten och sedan fortsätta. Låt säga att vi kastar tärning 10 gånger och beräknar medelvärdet. Sedan upprepar vi detta 10 gånger så att vi totalt får 10 medelvärden.
Jag gjorde precis detta (på datorn) och fick följande medelvärden:
2.9
2,8
3,2
3,5
3,9
3
3,3
3,4
3,4
3,4
Ritar man en graf över detta kan man se att utfallet börjar likna en normalfördelning.
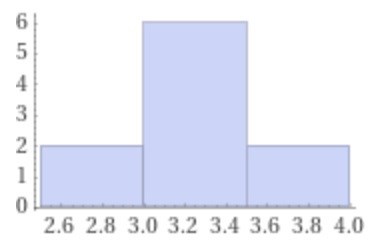
Det din definition av normalfördelning säger är att om vi skulle upprepa dessa försök in i oändligheten och fortsätta fylla på grafen med ny data så skulle den till slut bli en normalfördelning.
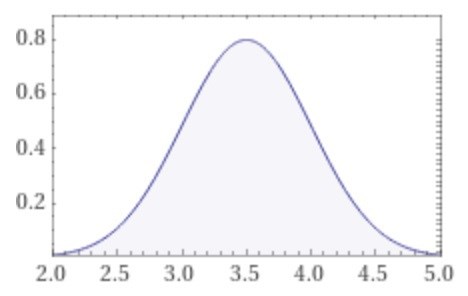
Tack, nu förstår jag lite bättre!
Just nu håller jag på att plugga om konfidensintervall och blir då lite fundersam över konfidensgraden. Vad avgör vilken konfidensgrad man ska sätta? Vad jag förstår är det vanligaste att man använder sig av 95%?
Men jag har ett exempel i boken där jag ska beräkna konfidensintervallet för mäns medelinkomst, där vi utgår från tabellen på nedanstående bild. Uträkningen de gjort i boken: 89.9 – 1.96 x 0.86 = 88.21 och sedan 89.9 + 1.96 x 0.86 = 91.59. Konfidensintervallet för männens medelinkomst är alltså 89.9 +/- 1.69.
Betyder de att de skattat konfidensgraden till 86%? I så fall, varför? 
Jag tolkar tabellen som att man har frågat 1540 st slumpvis utvald män och 1384 st slumpvis utvalda kvinnor vad de tjänar och kommit fram till "89,9" respektive "71,9", med standardavvikelserna 33,8 och 18,7. Oklart vad det är för enhet på detta eller om det är något slags indexmått, men det spelar mindre roll i detta fall (det står säkert någonstans i texten).
Om man vill skatta det faktiska värdet på mäns inkomst utifrån detta kan man ställa upp ett konfidensintervall. Beräkningen "89.9 – 1.96 x 0.86 och sedan 9.9 + 1.96 x 0.86 = 91.59" innebär att man har ställt upp ett tvåsidigt konfidensintervall med konfidensgraden 95%. Värdet 0,86 kommer från centrala gränsvärdessatsen. Om man skulle upprepa dessa intervjuer/mätningar av mäns inkomster skulle man få värden som har en standardavvikelse ungefär motsvarande 33,8/√1540=0,86. Värdet 1,96 kommer från en t-tabell för ett tvåsidigt 95%-igt konfidensintervall med 1540 st observationer.
Beräkningen man gör på slutet innebär att om man skulle upprepa mätningen så skulle man vid 95 av 100 gånger få ett intervall som innefattar medellönen hos män om vi hade frågat samtliga män va de tjänar.
Angående val av konfidensgrad så är det inte helt enkelt. 95% är någon sorts standard som folk väljer, ofta utan att tänka efter då det "är så man gör". Om man väljer en lägre konfidensgrad, t.ex. 80% så kommer man få ett bredare intervall. Väljer man en högre grad, t.ex. 99% får man ett snävare intervall.
Valet av konfidensgrad har stor betydelse vid hypotesprövning, t.ex. om vi hade velat dra slutsatser kring huruvida män tjänar annorlunda än kvinnor utifrån vår mätning. Låt oss ha hypotesen att det inte finns någon löneskillnad. En låg konfidensgrad skulle då göra det mindre troligt att komma fram till slutsatsen att män tjänar annorlunda än kvinnor eftersom intervallet för männens lön blir bredare, till slut är det så brett att det nästan säkert täcker även kvinnors skattade lön. Då skulle man dra slutsatsen att det inte finns några löneskillnader. Då är risken stor att man begår det som inom statistiken kallas för typ II-fel, alltså att man säger att det inte finns någon skillnad fast det i verkligheten finns en skillnad.
Väljer man istället en för hög konfidensgrad kommer man få ett snävare intervall för männens löner vilket gör att man lättare skulle dra slutsatsen att det finns en löneskillnad. Då ökar risken för ett typ I-fel, alltså att man säger att det finns en löneskillnad fast det egentligen inte gör det.
Hej igen!
Tack för så bra svar. Jag fortsätter att plugga på här och använder dina förklaringar för att försöka förstå.
Jag får dock inte kläm på vad centrala gränsvärdessatsen är. Jag vet att du skrivit lite om det men jag får inte riktigt ihop det. Som det står beskrivet i min bok så kan samplingsfördelningen (den fördelning som uppstår vid tillräckligt stort urval) med normalfördelning, enligt det matematiska beviset centrala gränsvärdessatsen. När jag frågar AI så får jag detta svar:
Centrala gränsvärdessatsen är en matematisk teori som säger att när man tar många oberoende och identiskt fördelade variabler och adderar dem tillsammans, kommer deras summa närma sig en normalfördelning oavsett fördelningen av de enskilda variablerna, förutsatt att stickprovens storlek är tillräckligt stor. Detta innebär att oavsett vilken fördelning de enskilda variablerna har, kommer sannolikhetsfördelningen av deras summa att närma sig normalfördelningen ju större stickprovet är.
Kan jag lita på AI i det här läget? Har du möjlighet till att ge något exempel på centrala gränsvärdessatsen? =)
Ja, AI har rätt. Centrala gränsvärdessatsen är det jag försökte beskriva med mitt exempel med tärningarna. Det bästa sättet att förstå hur det fungerar är nog att göra ett experiment. Plocka fram en tärning eller använd en digital tärning likt denna: https://www.online-tarning.se/
Steg 1: Kasta tärningen 60 gånger och räkna antalet gånger du får en 1:a, 2:a osv. Rita ett histogram över detta. Då kommer du förhoppningsvis få något som liknar en rektangelfördelning, vilket är den fördelning som tärningskast följer. Sannolikheten är lika stor för varje utfall 1-6.
Steg 2: Kasta tärningen 3 gånger och beräkna medelvärdet av dessa tre kast. Upprepa detta 20 gånger och rita ett nytt histogram över resultatet. Även denna gång har du kastat tärningen 60 gånger, men du kommer se att sannolikheten att få ett visst resultat ser helt annorlunda ut jämfört med i steg 1. Det kommer vara mer sannolikt att få ett resultat runt 3,5, dvs utfallet blir en normalfördelning.
Det är detta den centrala gränsvärdessatsen säger. Oavsett vilken fördelning vi har i steg 1 så kommer vi få ett utfall som liknar en normalfördelning i steg 2. Om vi beräknar oändligt många medelvärden får vi en perfekt normalfördelning. Ju fler gånger vi kastar innan vi beräknar medelvärdet, desto mindre blir standardavvikelsen i normalfördelningen. Grafiskt så blir då normalfördelningskurvan mer "toppig" med fler värden närmre 3,5.
