
Multipel linjär regression, fördelning för beta
Hej!
Jag behöver hjälp med att förstå hur man ska tolka fördelningen för beta i en multipel linjär regression.
Här är vad jag förstår:
När vi har en enkel linjär regression så kan man ju skriva slumpvariabeln för en linjär ekvation: Y_i = alpha + beta*x_i som:
, där X\bar symboliserar att det är medelvärdet för den variabeln. Vi antar här att alla Y_i är oberoende, normalfördelade och med gemensam varians sigma samt att följande samband för deras väntevärde är sant:
E[Y_i] = alpha + x_i*beta
Från dessa antaganden och från formeln för beta så kan man skriva om beta till:
som alltså är en linjär kombination av oberoende normalfördelade variabler vilket i sig blir en normalfördelad variabel. Sen kan man visa att den här estimatorn som är en funktion av slumpvariabler och därav en är även estimatorn en slumpvariabel, är unbiased då dess väntevärde är det "sanna" beta samt så har den en varias som beror på värdena på x.
Om man inte vet om sigma för Y_i~(alpha+x_i * beta, sigma), så kan man visa att
Och från detta kan man sen härleda en t-fördelning osv.
(Ovan är Y = Y_1,...,Y_n och dom hör ihop med x = (x_1,...,x_n))
Vad jag behöver hjälp med:
Jag förstår inte hur jag ska göra när vi har en multipel linjär regression. Överallt där jag kollar så går man över och kör på matrisform och den least square lösningen där är samma som vi lärde oss i Linjär Algebra:
, där
Och såhär långt är jag helt med men när man ska visa vilken fördelning beta har förstår jag inte riktigt, det jag hittar kommer från följande källa:
section15.pdf (mit.edu)
och där skriver man på sida 2 att:
Jag förstår dock inte variansen här, det blir ju en matris med p+1 rader och n kolumner och då blir ju variansen, för en specifik variabel i vektorn beta, en vektor av dimension n och inte ett reellt tal, eller missuppfattar jag detta?
Mitt mål är att förstå/se vilken normalfördelning som varje variabel i vektorn beta. Jag vill veta detta så att jag sen kan härleda med hjälp av en sats som säger att:
Om X~N(0,1) och Y ~ Chi-square(f) är oberoende så gäller att:
M.h.a detta kan jag sen visa att en viss variabel är t-fördelad.
Tack på förhand!

Variansen i den formeln är en (p+1)x(p+1) matris, det är alltså en matris där
så variansen i den vanliga meningen är diagonalelementen i den matrisen.
Givet n normalfördelade variabler så räcker det ju inte att ange deras väntevärde och varians för att specificera deras simultana fördelning, vi måste också ange deras kovarians.
Du är ju dock alltså av deras marginella fördelningar, jag känner inte på rak arm till ett enkelt uttryck för det men ställer man upp ML-ekvationerna explicit bör man väl kunna härleda det.
My bad, glömde att jag multiplicerar ihop matriserna så det blir (p+1)x(p+1), men jag känner mig fortfarande obekväm med att variansen beskrivs av en matris.
Anledningen till att beta i en enkel linjär regression blir normalfördelad är ju för att:
X~N(a,b), Y~N(c,d), Z = X+Y ~ N(a+c, d+b), men det kanske inte längre är möjligt att skriva beta i en multipel linjär regression som en linjär kombination av Y_1,...,Y_n?
Mitt mål är alltså att hitta ett uttryck för beta så att: beta_j ~ N(a,b) för några reella tal a och b. Det måste ju finnas eftersom man slutligen gör ett t-test för att beräkna p-värde och signifikans för ett givet beta_j i en multipel linjär regression.
Alltså du har fortfarande linjäritet,
β(Y) = (X^T*X)^(−1)*X^T*Y
är ett linjärt samband i Y.
Helvete just det. Ska se om jag kommer någon vart av att ställa upp ML-ekvationerna. Tack!
Hej igen, jag var nog inte helt med igår när jag tänkte på det här...
Men förstår jag det rätt om jag tänker på följande sätt:
Låt:
Vi vet att: \beta(Y) = (X^T*X)^(-1)*X^T*Y gäller, och (X^T*X)^(-1)*X blir en p x n matris. Om vi betecknar elementen i (X^T*X)^(-1)*X:
Så är ju:och
Jag kan alltså tilllämpa att V(X+Y) = V(X) + V(Y) då alla slumpvariable är oberoende. Och alla Y_i har gemensam varians sigma^2.
Tänker jag rätt?
Tillägg:
Fördelningen för slumpvariabeln beta_j (Y) blir då,
Du tänker tyvärr fel, observationerna Y är inte oberoende, det vi vet är att det har samma varians och att de är betingat oberoende, dvs oberoende för givna värden på kovariaterna, dvs residualerna är oberoende.
Du får istället:
så
vilket allså leder oss till formeln i din första post.
Men detta är också ett enklare uttryck! Titta på diagonalelement i matrisen (X^tX)^(-1), det är varianserna för motsvarande beta-parameter. Problemet för dina syften är att det nog inte finns ett snyggt ett snyggt slutet uttryck för detta men det kanske du inte behöver.
Sedan en liten sak, du verkar i din senaste post ha slarvat bort interceptet, så beta-vektorn börjar med en etta, och X-matrisen har en första kolumn som består av ettor. Alternativt så får du tänka att du normaliserar kovariaterna och susbstraherar genomsnittet av varje kolumn i X från elementen i den kolumnen.
Äsch jag tänker fel, klart observationerna är oberoende.
Sedan en liten sak, du verkar i din senaste post ha slarvat bort interceptet, så beta-vektorn börjar med en etta, och X-matrisen har en första rad som består av ettor. Alternativt så får du tänka att du normaliserar kovariaterna och susbstraherar genomsnittet av varje kolumn i X från elementen i den kolumnen.
Tack så mycket för svaren! Sorry, jag var lite otydlig men jag tänkte att jag håller beteckningen helt generell men att man då för intercepter har att x_11 = ...=x_n1 = 1 och att beta_1 blir det som jag betecknade som alpha förut. Skrev såhär nu för att det kändes lättare att få ett "snyggare" uttryck tillslut.
Men om man då antar att Y_1, ..., Y_n är oberoende då kan man skriva som jag gjorde men om det endast gäller att de är betingat oberoende så blir det som du skrev?
Förstår jag dig rätt då?
Nä jag tänkte helt knäppt, de är helt oberoende så man kan göra som du skrev, men det jag skrev stämmer också, formlerna ser olika ut men det är för att vi har olika matriser.
Men din formel är ju då lite tillkrånglad men den funkar, jag vet inte om det är så att du har lite svårt för kovarians-varians matrisen som begrepp och hellre skriver om det så där så går det bra.
Men du borde verkligen se till att du förstår kovarians-varians matrisen också.
https://en.wikipedia.org/wiki/Covariance_matrix
Min enda erfarenhet av kovarians - varians matrisen är att man för godtyckliga slumpvariabler
X_1,...,X_N så blir Var(a_1*X_1+ ...+ a_n*X_N) =
där a_i är konstanter för i = 1, ..., N
Vilket man sen kan skriva om på matrisform till:
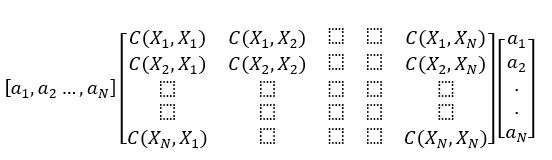
Har härlett ovan själv så kanske är fel, men oavsett har jag hitills haft lite att göra med den matrisen och det har mer varit praktisk notation än något annat. Men den kanske har en hel del intressanta egenskaper, ska kolla in Wikipedia-artiklen du länkade!
Tack för all hjälp :)
Det är som är viktigt här är egentligen:
Om X är en n-vektor av slumpvariabler med kovariansmatris S och A är en nxn matris så har vektorn AX kovariansmatrisen ASA^t.
Hej igen,
Tänkte lite på det här med variansen igen för beta estimatorn. Jag förstår att alla representerar det på matrisform men om jag ändå vill ha ett "explicit" uttryck likt det jag fick ovan i fallet där variansen inte är konstant och vi inte har oberoende variabler. Borde inte den slumpmässiga variablen beta:
Ha variansen:
Och givet att summan av beroende normalfördelade variabler är normalfördelad så borde väl fördelningen bli:
Eller?
Om detta är sant så borde det enda kravet för att ovan fördelning ska stämma vara att det förväntade värdet för error-termen ska vara noll, givet icke-stokastiska regressors?
