
Numberphile video om Steins paradox
Jag såg precis den här videon från Numberphile:
https://www.youtube.com/watch?v=FUQwijSDzg8
Och in a nutshell innebär paradoxen att iid normalfördelade vektor av observationer av sanna värden under minstakvadratfelmetriken och L2 normen INTE är admissible, alltså att i sig inte är den bästa approximatorn. Detta vid dimensioner 3 eller större.
Den bästa approximatorn är denna skalning av observationerna:
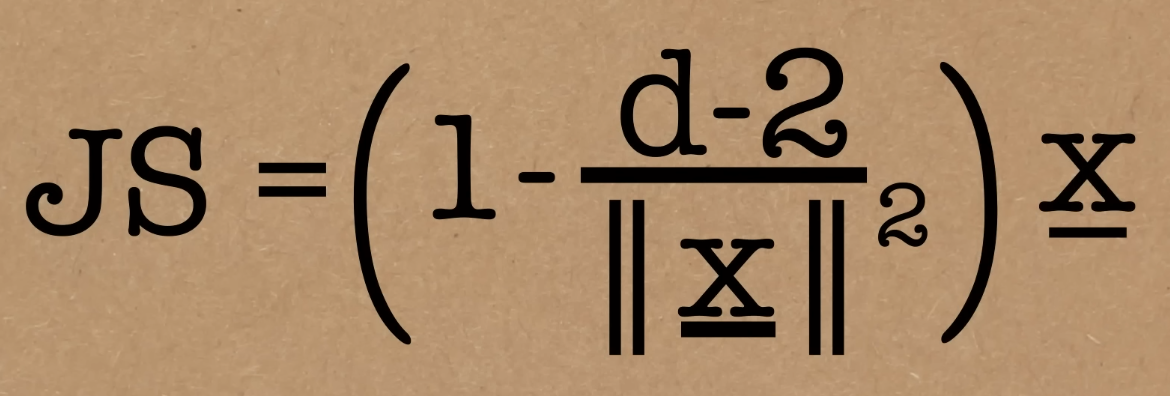
Och anledningen är att:
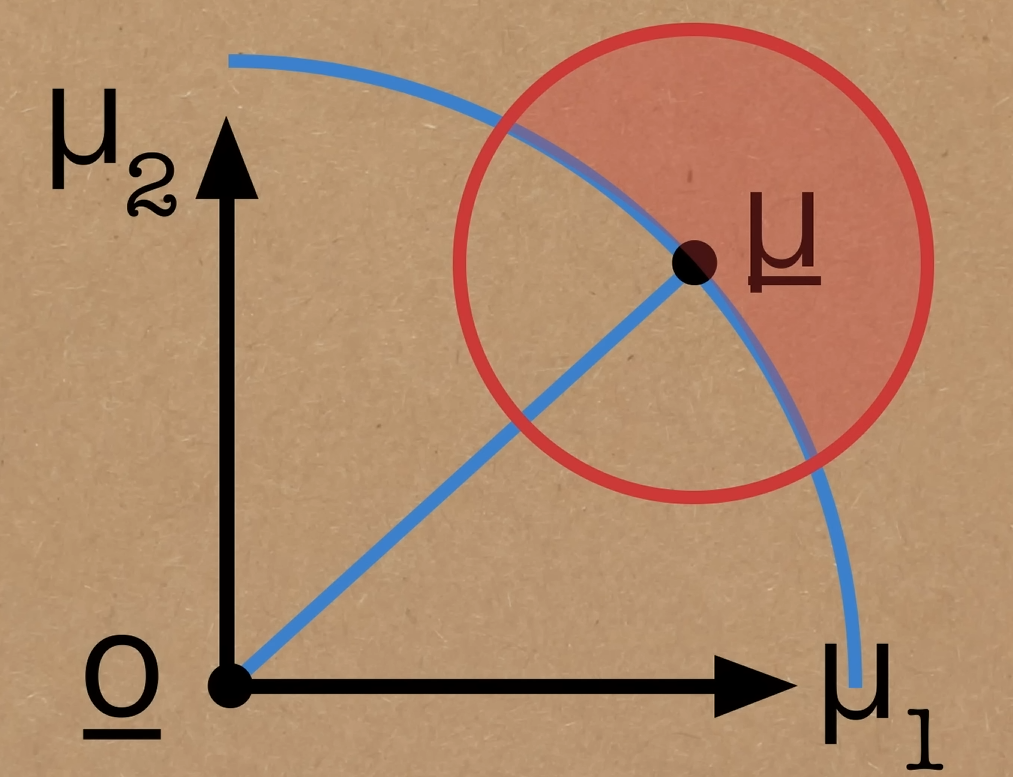
Jag tolkar det som en störig effekt av valet av norm i högre dimensioner. Alltså i bilden ovan hade vi med taxinormen fått två diamanter och den blåa cuttat den röda i mitten. Men professorn i videon verkar tycka att det är ett djupare resultat:
... and whats so paradoxical about that is i will have used information about the price of the sandwich and the weights of cats i order to modify the data i got on the temperature of the office to get a better estimate... [trots att de är iid]
Vilket kanske är lite bait för youtube, jag vet inte, tycker jag rätt här?
OCH, varför funkar paradoxen inte för d=2?

Spännande, hade inte hört om detta förut! Tack för tipset!
Jag är lite osäker på vad du menar med iid. Jag hade nog sagt att vi har en (1) observation av . Och att observationen x inte är den bästa skattningen av i en MSE-mening. Det är säkert sant att detta är ett resultat av att man val MSE som metric och andra metrics har andra egenskaper. Dock är ju MSE en vanlig metric troligtvis pga dess koppling till maximum likelihood-skattaren av i detta fal (men som jag förstår klippet så är det inte strikt nödvändigt att ha en normal-fördelning så det argumentet faller kanske lite idk).
Men jag kan ändå hålla med vad de säger i videon (det du skriver i inlägget): det är motsägelsefullt att du observerar variabler som är oberoende från varandra, sedan för att göra skattningen skalar du dina värden med en faktor som beror på alla observerade värden och får helt plötsligt en bättre skattning av .
Jag undrar dock om det där sista är en nyckel: skattningen av hela vektorn blir i snitt bättre. Men frågan är om att ta hänsyn till priset på en macka på andra sidan jorden och andra grejer de nämnde, när man skattar temperaturen i rummet, gör det att felet för skattningen av temperaturen blir bättre? Någon som vet?
Side note: måste vara bland de sämre illustrationerna av ett neuralt nätverk för att klassificera hundar och katter som någonsin gjort på YouTube? Själva nätverket ser inte bra ut, men framförallt så om man bara tittar på vad de illustrerar som output (och inte lyssnar på vad de säger) verkar det snara som att de har ett nätverk som genererar bilder än klassificerar dem?
Känns också som detta kan vara relaterat på något sätt till det lite paradoxala att normen av en normalfördelad vektor är typ -fördelad (alltså 0 är inte värdet med högst pdf) eller i andra ord, om du har massa vektorer från en kommer de tendera att ligga på en sfär (beroende på dimension) runt origo
Nej nej, jag är helt med på att estimatorn JS är bättre än X, men tycker inte det är lika djupt som professorn vill få det att låta. Det är bara en konsekvens av valet av norm, paradoxen kan lösas genom att byta norm.
Haha, bara för att man vet anledningen kan man väl fortfarande tycka att det är en paradox?
Jag kan nog tycka att det är paradoxalt: varför skulle jag skala min observationer av oberoende variabler med en faktor som faktiskt beror på de andra observationerna?
