
Sannolikslära
Visa spoiler
Skriv ditt dolda innehåll här
Hur ska jag tänka här? Tack på förhand. 

Behöver man inte veta hur många lampor som testades? Har man så avancerad statistik i Matte 1?

Laguna skrev:Behöver man inte veta hur många lampor som testades? Har man så avancerad statistik i Matte 1?
Detta är nog ett klassiskt exempel på hur författare slängt in en uppgift utan att förstå hur komplicerad den faktiskt är. Sen saknar vi ju information om de ens pratar om samma konfidensgrad. För om de inte gör det, kan vi ju direkt säga att det mycket väl kan vara så att båda talar sanning om Tilde pratar om en högre konfidensgrad än det Tobias gör.
Om vi förmodar de pratar om samma konfidensgrad kan man med väldigt mycket aritmetik komma fram till att det inte kan vara så att båda kan ha rätt samtidigt. Men man kan ju till exempel absolut inte motivera det med något enkelt som att 0,03•2 < 0,11-0,04. Det är betydligt mer komplicerat än som så... Man kan inte heller dra slutsatsen att det skulle kunna vara så att båda talade sanning bara för att de två konfidensintervallen faktiskt överlappar. För "felmarginalen" för dag två blir ju 0,0479 ungefär oberoende av konfidensgraden som Tobias använde, men det att 0,0479+0,03 > 0,11-0,04 kan vi inte använda till att dra någon slutsats. För att de två konfidensintervallen med konfidensgrad m överlappar varandra innebär INTE att man kan dra slutsatsen att skillnaden inte är statistiskt signifikant på konfidensgraden m. Ser att flera böcker felaktigt verkar tro detta. Var detta en uppgift från en tryckt bok? I så fall vilken?
Här är en förklaring som inte gör grova förenklingar som härleder varför de inte kan ha rätt samtidigt om de talar om samma konfidensgrad:
Denna uppgift är på TOK för hög nivå för att vara med i Matematik 1. Åtminstone om man ska svara hyfsat korrekt på den. Från vilken bok var detta?
Om vi börjar räkna på det kan vi se:
Låt oss förmoda konfidensgraden är 0.95 och att vi utför normalapproximation av binomialfördelning (egentligen är det ju hypergeometrisk men blir väl krångligt). Då kan vi härleda n från Tobias påpekande enligt
vilket ger
Av uppgiften känns det rimligt att förmoda att det testades lika många lampor även dag två. Av detta kan vi därmed skapa ett konfidensintervall för förändringen enligt
vilket innebär att "samma felintensitet" befinner sig utanför konfidensintervallet. Detta indikerar en statistiskt signifikant skillnad i felintensitet på konfidensgraden 0.95 och att det skulle innebära att Tilde har fel om Tobias hade rätt och båda pratade om konfidensgraden 0.95. Detta vare sig bevisar eller motbevisar om huruvida de kan ha rätt samtidigt för vi har ju gjort ett förmodande att de pratar om samma konfidensgrad och dessutom specifikt 95%. Sen är det ju egentligen en hypergeometrisk fördelning då det tycks vara stickprov utan återläggning men orkar inte, då blir det ju ännu mer komplicerad fråga... :) Men då kvoten mellan stickprov och totalpopulationen är 0.04 väljer jag att förenkla det och såvida inte det är close-call på slutsatsen kan vi göra det med gott samvete...
Om vi nu allmänt förmodar Tobias har rätt och vi skapar konfidensintervall genom att gå k stycken standardavvikelser åt var sida (alltså inte nödvändigtvis 1,96), får vi, om inte jag tänker fel, att Tildes uttalandes sanningsvärde (under förmodandet att Tobias talar sant och antal kontrollerade lampor var exakt lika många och de dessutom pratar om samma konfidensgrad) är ekvivalent med (om ni undrar substituera jag i inne i rotuttrycket i formeln för konfidensintervall för skillnad i andelar mellan två stickprov där k är antal standardavvikelser vi låter vara med i våra konfidensintervall och m är påstådd felmarginal som Tobias gör för första dagen). Vi får då till slut att Tildes uttalandes sanningsvärde är ekvivalent med
under förmodandet att Tobias talade sanning, alltså en falsk utsaga helt oberoende av k faktiskt. Och då det egentligen var en hypergeometrisk fördelning är dessutom 0.05652 en svag överskattning så allt är bra och robust. Detta visar att oavsett vilken konfidensgrad de båda talar om (men den är samma de två i mellan), så implicerar det att om Tobias talar sanning så ljuger Tilde och vi kan gå andra hållet och därmed visa att om Tilde talar sanning måste Tobias ljuga. Därmed har vi att vi inte kan ha situationen att de båda talar sanning. Men hålla? Vad gör denna uppgift i Matematik 1???
stevie_86 skrev:Visa spoiler
Skriv ditt dolda innehåll här
Hur ska jag tänka här? Tack på förhand.
Hur kom du över denna uppgift? Var det i en bok eller en uppgift din lärare gav er separat? Uppgiften är milt sagt konstig...

Jag tror att vi överteoretiserar här!
Om båda ska ha rätt måste de finnas en (normal?) fördelning som på vald signifikansnivå (okänd) rymmer båda dagarnas observerade värde dvs 4 och 11. Felmarginalen vid vald signifikansnivå är 3 procentenheter. Alltså är ökningen inte signifikant på vald nivå om felfrekvensen har medelvärde 7,5 eftersom båda dagarna ryms inom felmarginalen.
matsC skrev:Jag tror att vi överteoretiserar här!
Om båda ska ha rätt måste de finnas en (normal?) fördelning som på vald signifikansnivå (okänd) rymmer båda dagarnas observerade värde dvs 4 och 11. Felmarginalen vid vald signifikansnivå är 3 procentenheter. Alltså är ökningen inte signifikant på vald nivå om felfrekvensen har medelvärde 7,5 eftersom båda dagarna ryms inom felmarginalen.
Om felmarginalen var 0.03 när andelen var 0.04 kommer felmarginalen vara ca 0.0479 när andelen är 0.11, för vi kan ju förmoda samma n givet det de säger i uppgiften. Då 0.03+0.0479 > 0.07 är det därmed inte så enkelt, för de två konfidensintervallen överlappar. Av detta kan vi inte dra någon slutsats alls faktiskt (Vi kan alltså INTE bara av det heller säga att de båda kan tala sanning). Det är just därför uppgiften faktiskt blir rejält komplicerad. Ser flera böcker som på olika sätt gör fel med detta. Ivern att trycka upp böcker efter den nya läroplanen för matematik 1 verkar ha trumfat vettig korrekturläsning.
Men som jag vill se det: Vi har en stokastisk variabel, antal fel per dag, två skattningar av medelvärdet 4 resp 11 och om Tobias har rätt en skattning av ett spridningsmått nämligen felmarginalen 3 procentenheter.
Om dess medelvärde är t.ex. 7.5 så ryms båda dagarnas resultat inom felmarginalen och då har ju Tilde rätt, alltså kan båda ha rätt.
matsC skrev:Men som jag vill se det: Vi har en stokastisk variabel, antal fel per dag, två skattningar av medelvärdet 4 resp 11 och om Tobias har rätt en skattning av ett spridningsmått nämligen felmarginalen 3 procentenheter.
Om dess medelvärde är t.ex. 7.5 så ryms båda dagarnas resultat inom felmarginalen och då har ju Tilde rätt, alltså kan båda ha rätt.
Förklara gärna mer noggrant vad du menar.
Men som jag vill se det: Vi har en stokastisk variabel, antal fel per dag, två skattningar av medelvärdet 4 resp 11 och om Tobias har rätt en skattning av ett spridningsmått nämligen felmarginalen 3 procentenheter.
Om det finns någon fördelning (alltså något medelvärde) som tillåter detta på vald signifikansnivå så har Tilde rätt.
Tyvärr tofflade jag till det ordentligt på upploppet - de båda medelvärdesskattningarna ryms inte inom 3%enh från något värde...
Och därmed borde min slutsats varit att de inte båda kan ha rätt.
Men sen tillkommer ditt påpekande att felmarginalen är olika för 4 och 11% fallen ...

Varifrån kommer uppgiften? Är det verkligen någon som påstår att det här är en Ma1-uppgift?
Jag har svårt att se att Tobias har rätt här,eftersom det inte går att utesluta slumpen.
Tobias menar att resultatet i själva verket kan vara mellan 1-7% den första dagen. Låt oss säga att felmarginalen är konstant,(även fast det inte står i texten), och vi säger att antalet trasiga lampor är 7% den första dagen. Den andra dagen är antal trasiga lampor 11%, och med felmarginalen inräknad, 8-14%.
Så även fast felmarginalen är i ytteränden, så är den första dagen 7 % och andra 8 %.
Detta är den ända lösningen jag har, inte en aning om det är det rätta svaret.
Denna uppgift är från ma1, jag har iaf fått den som en uppgift 🙂
stevie_86 skrev:Jag har svårt att se att Tobias har rätt här,eftersom det inte går att utesluta slumpen.
Tobias menar att resultatet i själva verket kan vara mellan 1-7% den första dagen. Låt oss säga att felmarginalen är konstant,(även fast det inte står i texten), och vi säger att antalet trasiga lampor är 7% den första dagen. Den andra dagen är antal trasiga lampor 11%, och med felmarginalen inräknad, 8-14%.
Så även fast felmarginalen är i ytteränden, så är den första dagen 7 % och andra 8 %.
Detta är den ända lösningen jag har, inte en aning om det är det rätta svaret.
Nej det är inte det Tobias säger. Han säger att om man ska döma från stickprovet är sannolikheten att den verkliga andelen är i intervallet 0.01 till 0.07 en viss konfidensgrad, till exempel 95%. Du har missförstått innebörden av felmarginal. Det är inte något absolut gräns som garanterar att det verkliga värde inte kan vara utanför. Sannolikheten att det verkliga värdet var utanför är 5% om man skapar ett konfidensintervall med konfidensgraden 95% och 1% för konfidensgraden 99%.
Felmarginalen är inte en konstant, den är beroende av både stickprovets storlek, andelen som visade sig vara sönder men även faktiskt delvis av antal lampor de producerade om man ska vara helt korrekt då de antagligen hade en procedur som gjorde att de inte kunde råka testa samma glödlampa mer än en gång av en slump. Man kan ABSOLUT inte bara säga att felmarginalen också är 3% för dag 2. Det är fullständigt tokigt och jag hoppas inte din lärare tror detta.
Om stickprovet var lika stort blir felmarginalen den andra dagen ca 4.79%. Alltså överlappar konfidensintervallen varandra. Men detta betyder inte att man kommit fram till att de båda kan ha rätt. Säger din lärare så är det precis lika tokigt. Så det är svårt att inte dra slutsatsen att den som har ställt frågan inte har koll. Så använd inte mer energi på denna fråga. Men säg gärna ifrån till din lärare att uppgiften anses vara fel ställd och olämplig. För det går inte ens att ha någon givande diskussion kring frågan.
Beräkningarna och kunskapen hur statistik fungerar som man behöver för att reda ut att de faktiskt inte kan tala sanning samtidig (om vi kan anta de båda uttalar sig på samma konfidensgrad) är så omfattande att det varit kontroversiellt att ha den som fråga på ett skriftligt prov i Matematisk Statistik på universitetsnivå. Så den har ingenting att göra i Matematik 1.
stevie_86 skrev:Denna uppgift är från ma1, jag har iaf fått den som en uppgift 🙂
Varifrån kommer uppgiften? Säg inte bara "Jag fick den av min lärare" för det är inte det jag undrar.
Jag läser på distans matematik 1, varifrån uppgiften kommer ifrån vet jag inte, har fått den som en av mina deluppgifter som vi har varje vecka! Känns som jag blir påhoppad här, jag ville bara ha hjälp med en uppgift av folk som är betydligt bättre på detta än mig och jag försöker lösa uppgiften efter vad jag tror är rätt, men har förstått att denna uppgift verkar vara för avancerad för ma1, varför vi har fått denna uppgift vet jag faktiskt inte.
Var läser du matte? Vem är det som ordnar kursen?
Fråga din lärare vilka moment i Ma1 som uppgiften handlar om.Han eller hon borde kunna svara på det, annars är det illa.
Det är inte dig vi hoppar på, det är den som har givit dig uppgiften som har gjort fel, tycker vi.

Min Matte5000 1c har liknande beskrivningar av signifikans. Har gjort flera uppgifter som följer samma beskrivning. 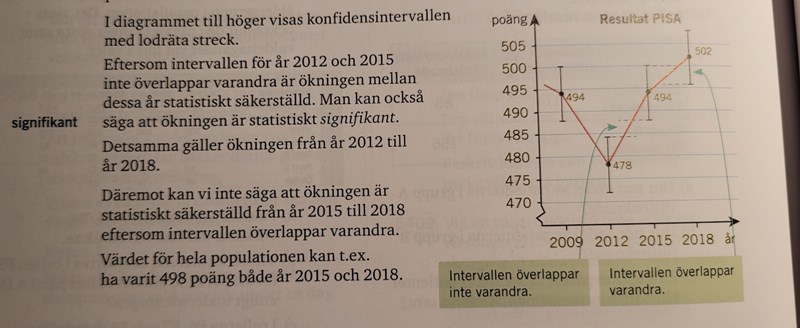
Oscar Jörke Hellberg skrev:Min Matte5000 1c har liknande beskrivningar av signifikans. Har gjort flera uppgifter som följer samma beskrivning.
Wow. Tack.
Det där är också kalasfel. Jag tror jag nu är uppe i 4-5 olika böcker i Matematik 1 som jag sett på ett eller annat sätt gör exakt detta felet, men detta var kanske det mest tydliga och allvarliga just för hur bastant de påstår det som inte stämmer.
Nu vet jag att exemplet ovan inte handlar om andelar men de exakta formlerna för när de är allmänna observationer av värden är lite krångligare men principiellt är problematiken den samma när de gör som de gör, för vi får student t-fördelning i stället i deras exempel men det blir samma feltänk vilket som. Lägger man ihop eller tittar på skillnaden mellan två oberoende undersökningar kan man inte addera standardavvikelserna, det är varianserna man ska addera. Standardavvikelsen för skillnaden mellan två undersökningar är mindre än summan av dessa två undersökningarnas individuella standardavvikelser. Man skulle kunna tänka på det som Pythagoras Sats faktiskt om de är oberoende och den nya standardavvikelse blir längden på hypotenusen, inte summan av kateternas längder.
Jag skriver därför om skillnad i andelar just för att det lite tydligare belyser problematiken rent aritmetiskt: Om man skapar två konfidensintervall för två olika andelar med en viss konfidensgrad och sedan ser att dessa intervall inte överlappar så är det korrekt att man kan dra slutsatsen att skillnaden i andelar är statistiskt signifikant på den använda konfidensgraden, dock är det egentligen inte så man avgör det. För nu kommer ett STORT men som gör hela uppgiften totalt fel:
Vi kan INTE dra slutsatsen att skillnaden inte är signifikant på den använda konfidensgraden bara för att två konfidensintervall överlappar. Nej, nej och åter nej. Det de skriver på de fem sista raderna är fullständigt fel och ett riktigt grovt fel dessutom.
För att avgöra om en skillnad i andelar är statistisk signifikant kontrollerar man om
k*rotenur(p1•q1/n1+p2•q2/n2) < |p1-p2|
(kan inte typsätta via telefonen men hoppas ni fattar)
där p1 är andelen i första undersökningen och p2 är andelen i andra undersökningen. q1=1-p1 och q2=1-p2 och k är antal standardavvikelser som man måste gå "åt sidan" åt båda hållen för att arean under den standardiserade normalfördelningskurvan ska motsvara konfidensgraden (så för konfidensgraden 0.95 (95%) blir k den klassiska 1.96.)
Det de skriver i boken innebär att de i stället tittar om
k(rotenur(p1•q1/n1)+rotenur(p2•q2/n2)) < |p1-p2|
Helt fel test för att svara på den fråga de påstår de vill svara på med andra ord. På grund av att vänsterledet i deras felaktiga test alltid är större än vänsterledet i det faktiska test som svarar på frågan (den olikheten jag skrev först) kan man ju som jag skriver helt först förvisso dra slutsatsen att skillnaden är signifikant på denna konfidensgrad om konfidensintervallerna inte överlappar. Men man kan alltså inte dra slutsatsen att skillnaden inte är signifikant på denna konfidensgrad bara för att de överlappar!
Detta är viktigt då man med den metodiken ofta felaktigt kommer dra slutsatsen att man inte kan dra en statistisk slutsats!!! Man slänger alltså undersökningar som kan peka på något på ett starkt sätt i soptunnan när vi i stället borde ha dragit slutsatsen att vi kunde påvisa något med en viss efterfrågad säkerhet. Detta är ett enormt slöseri och måste undvikas att läras ut.
Oscar Jörke Hellberg skrev:Min Matte5000 1c har liknande beskrivningar av signifikans. Har gjort flera uppgifter som följer samma beskrivning.
Alltså, det korta svaret varför man inte alls kan göra som de gör beror egentligen helt enkelt på att
men i och med allmänt gäller för positiva a och b innebär det förvisso att man kan dra slutsatsen att skillnaden är signifikant på en viss konfidensnivå om de två konfidensintervallen inte överlappar. Men det beror ju på denna olikhet. För man har ju egentligen använt helt fel metod och "kollat på helt fel sätt" om man säger så. Därmed borde man inte lära ut "kontrollera om konfidensintervallen överlappar" som metod alls, för risken att man då tror man inte kan dra slutsatsen att förändringen är signifikant på denna konfidensnivån bara för att man ser att konfidensintervallen inte överlappar är stor. I synnerhet om boken rakt ut hävdar denna villfarelse.
Vad som du beskrev är nog lite för komplext för mig, men jag förstår iaf. helheten. Blev väldigt konfundersam när jag arbetade med detta. Visst, det finns en hel del poänger i vad de säger, men hela konceptet kändes avklätt och konstigt.
Borde jag uppmärksamma min lärare och isf. vad säger man?
Oscar Jörke Hellberg skrev:Borde jag uppmärksamma min lärare och isf. vad säger man?
Ja det tycker jag. Det är så pass grovt fel. Viktigt att man undviker den uppgiften kommande år. Du kan ju hänvisa till denna tråd om de inte köper dina påpekanden.
Det är fler olämpligheter faktiskt i denna uppgift. Man bör först och främst säga statistiskt signifikant och dessutom alltid även direkt påpeka på vilken nivå (konfidensgrad). Uttrycket statistiskt säkerställd är dumt då det lätt skapar illusionen av att man BEVISAT något. Det är ganska sannolikt att de här syftar på konfidensgraden 0.95 (95%), men man ska inte behöva förmoda detta. Man måste påpeka den!
Här säger de först och främst statistiskt säkerställd (vilket är en beteckning man helst ska undvika även om den tyvärr används ibland samhället särskilt när personer vill dra för stora växlar av en studie), men det är helt tokigt att då inte ens säga på vilken nivå (konfidensgrad). Uppgiften slösar bara tid hos eleverna och förvirrar mer än den klargör.
