Exempelfråga
Hej!
Det här är ingen uträkning jag behöver hjälp med utan teorin.
Jag undrar varför sannolikheten för att grisen hamnar på sidan är mer tillförlitlig? Vad avgör hur tillförlitlig något är? Påståendet i fråga är sista meningen i sista stycket.


Tänk dig att vi gör 50 nya kast och får 34 "fläsklägg". Då kommer den relativa frekvensen bli 0,68 (inte så värst stor skillnad jämfört med 66 %, en ökning med cirka 3 % bara). Om vi får 2 "grishals" i stället för 1 kommer den relativa frekvensen att fördubblas - en stor skillnad.
Så det är för att en ändring av frekvensen i de övriga utfallen skulle få dess relativa frekvens att öka mycket, rent procentuellt?
Om du menar det som jag tror att du menar - ja.

StudieRo skrev:Så det är för att en ändring av frekvensen i de övriga utfallen skulle få dess relativa frekvens att öka mycket, rent procentuellt?
Nej, det boken skriver är högst förvirrande i största allmänhet. Men det är bra du är nyfiken på teorin bakom. Fortsätt vara så nyfiken! Jag har provat reda ut vad det handlar om här.
Det korta svaret på din fråga är att boken har fel. Det är större osäkerhet kring sannolikheten för att grisen hamnar på sidan än för alla de övriga utfallen. Det är tråkigt att se sånt här, men jag är tyvärr inte förvånad.
Det absolut viktigaste att ta med sig från detta är att den relativa frekvensen vi får enbart är en skattning av sannolikheten. Det ÄR inte sannolikheten. På ett sådant begränsat försök med enbart 50 observationer är detta fullständigt essentiellt att skilja på. Som till exempel bör vi alltså inte börja räkna på vad sannolikheten att få 8 fläsklägg i rad är på bakgrund av skattningen och då svara . Nej, nej och åter nej. Osäkerheten kring vad sannolikheten att få 8 fläsklägg i rad är fortfarande extremt hög och vi bör inte ens pröva uttala oss om den än. Så ivrigt bör vi inte bolla vidare med detta alls. Tyvärr ser jag detta har gjorts ibland, till och med på nationella prov, vilket är mycket synd/hemskt. Så viktigt är det att skilja på en given etablerad sannolikhet och en skattning av en sannolikhet. Detta är det KLART viktigaste informationen kring detta man i Matematik 1 bör fånga upp.
Låt mig prova förtydliga vissa saker här:
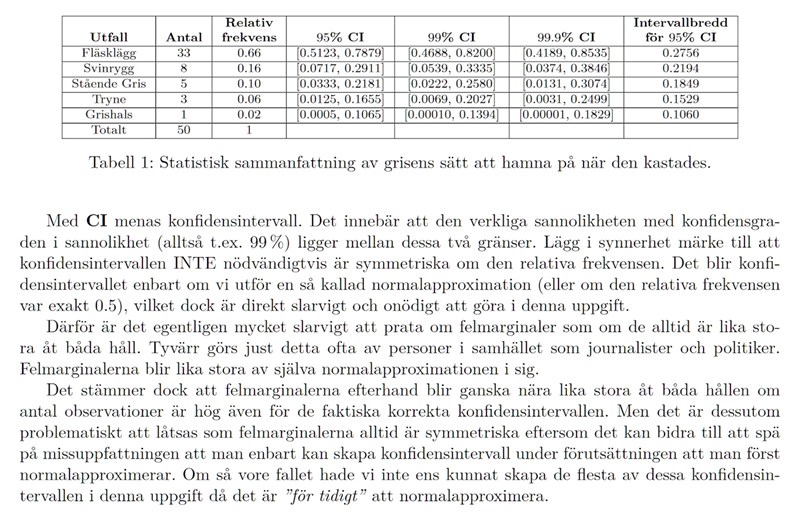
För det första är osäkerheten i de faktiska sannolikheterna mindre för utfall som antingen inträffar väldigt sällan eller inträffar väldigt ofta jämfört med saker som ungefär inträffar varannan gång. Boken tycks hejdlöst blandat ihop olika saker här. Bredden på konfidensintervallet för fläsklägg kommer vara störst av de olika observationerna, inte minst! Detta är dessutom oberoende av vilken konfidensgrad vi väljer. Däremot är lämpligheten att börja normalapproximera betydligt bättre för fläsklägg än för de övriga, just eftersom variansen är högre. Än så? Det är nog detta de blandat ihop med tillförlitlighet i boken.
Ja, vi kan med mer tillförlitlighet normalapproximera andelen som landar på fläsklägg, men det i sig gör inte skattningen mer tillförlitlig än de övriga, det är faktiskt tvärt om. Dessutom är det är ju ingenting som säger att man måste normalapproximera. För data som detta bör man helst låta bli faktiskt! Denna insikt är viktig för att till exempel inte slösa tid på att hitta tillräckligt många som svarar (för att kunna normalapproximera) på en enklare fråga om man utför en mindre enkätundersökning där man bara vill se om fler föredrar A över B och det tidigt lutar starkt åt ena hållet. Enorma mängder tid slösas bort på detta varje år.
Den faktiska sannolikheten för ett utfall kan vi anta faktiskt finns, men vi vet ej dess faktiska värde. Givet de observationerna vi gjort kan vi alltid skapa ett konfidensintervall för den faktiska sannolikheten. Ett konfidensintervall måste alltid anges med en konfidensgrad. Till exempel 99%. Det innebär att man skapar ett intervall där det är 99% sannolikhet att den faktiska sannolikheten befinner någonstans i intervallet. Det man hittar då är en nedre och övre gräns som anger "vid vilka gränser blir det så osannolikt att det verkliga värdet är utanför dessa gränser, givet vad vi observerat, att vi med t.ex. 99% säkerhet har att det faktiska värdet är i detta intervall." Vid tvåsidigt begränsade konfidensintervall som görs i bilden under ser man dessutom till att halva av den resterande sannolikheten (alltså 0.5% och vi har konfidensgraden 99%) hamnar innan konfidensintervallet och den andra halvan hamnar efter konfidensintervallet.
När man då syftar på att en sannolikhet är mer tillförlitlig än en annan syftar man då på att bredden på konfidensintervallet är smalare än en annan sannolikhet. Om man av någon anledning menar att syfta på något annat måste man i så fall tydligt ange detta, som till exempel urvalsfel, dåligt formulerade alternativ osv...
I exemplet från boken kan vi för varje utfall skapa konfidensintervall. Låt oss skapa tvåsidiga konfidensintervall med konfidensgraden 95%, 99% och 99.9% för att belysa hur det kan se ut.